Scan operation
The Scan Operation is executed on a Datastore to assert the data quality checks defined for the named collections of data (e.g. tables, views, files, topics) within it. The operation will:
- produce a record anomaly for any record where anomalous values are detected
- produce a shape anomaly for anomalous values that span multiple records
- record the anomaly data along with related analysis in the associated Enrichment Datastore
Info
To assert data quality checks to find anomalies, a user needs to perform a Scan operation.
- Scan operation enables the user to assert the checks in incremental vs full loads, with options to limit the number of records, run a scan on a select list of tables / files, and to set schedules for future scans.
Operation Configuration
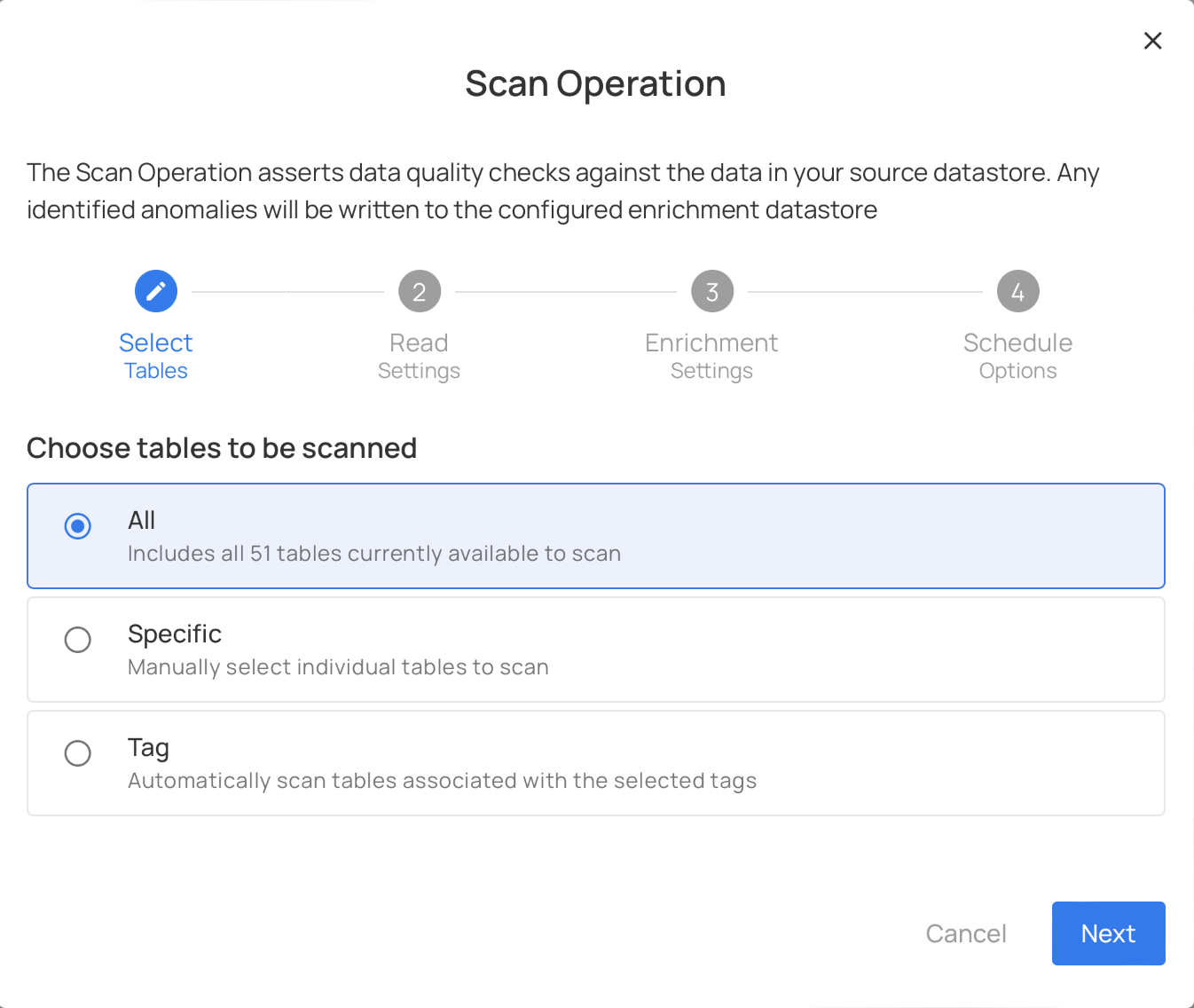

A Scan Operation can be configured with the following options:
Full
To process all records ignoring the previous scan.
Incremental
To scan only new data updated since the previous scan.
Info
When running an Incremental Scan for the first time, Qualytics automatically performs a full scan, saving the incremental field for subsequent runs.
-
This ensures that the system establishes a baseline and captures all relevant data.
-
Once the initial full scan is completed, the system intelligently uses the saved incremental field to execute future Incremental Scans efficiently, focusing only on the new or updated data since the last scan.
-
This approach optimizes the scanning process while maintaining data quality and consistency.
Record limit
To limit the total number of records scanned.
Target selection
- You can select to all tables.
- To target only a subset of the available named collections.
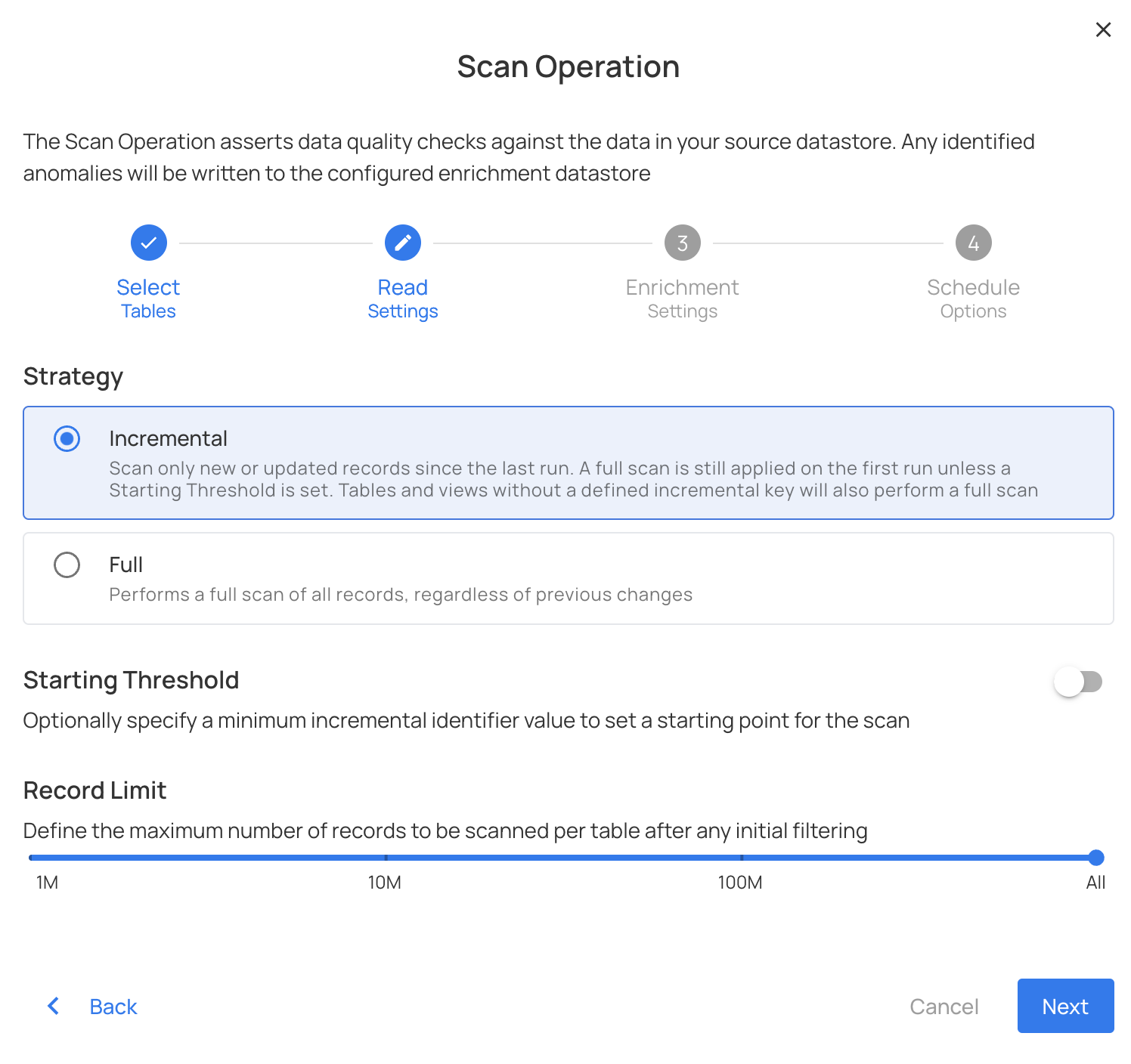
Starting Thresholds:
Greater Than Time:
Applicable only to profiles with an incremental timestamp strategy.
Users can define a starting point based on incremental timestamps, allowing the analysis to focus on data beyond a specified time threshold.
Greater Than Batch:
Applicable only to profiles with an incremental batch strategy.
Users can set a beginning point by specifying a batch threshold. This ensures that the analysis concentrates on data beyond a defined batch number.
-
Remediation strategy- To specify how enrichment tables should be migrated to reflect changes in source tables.
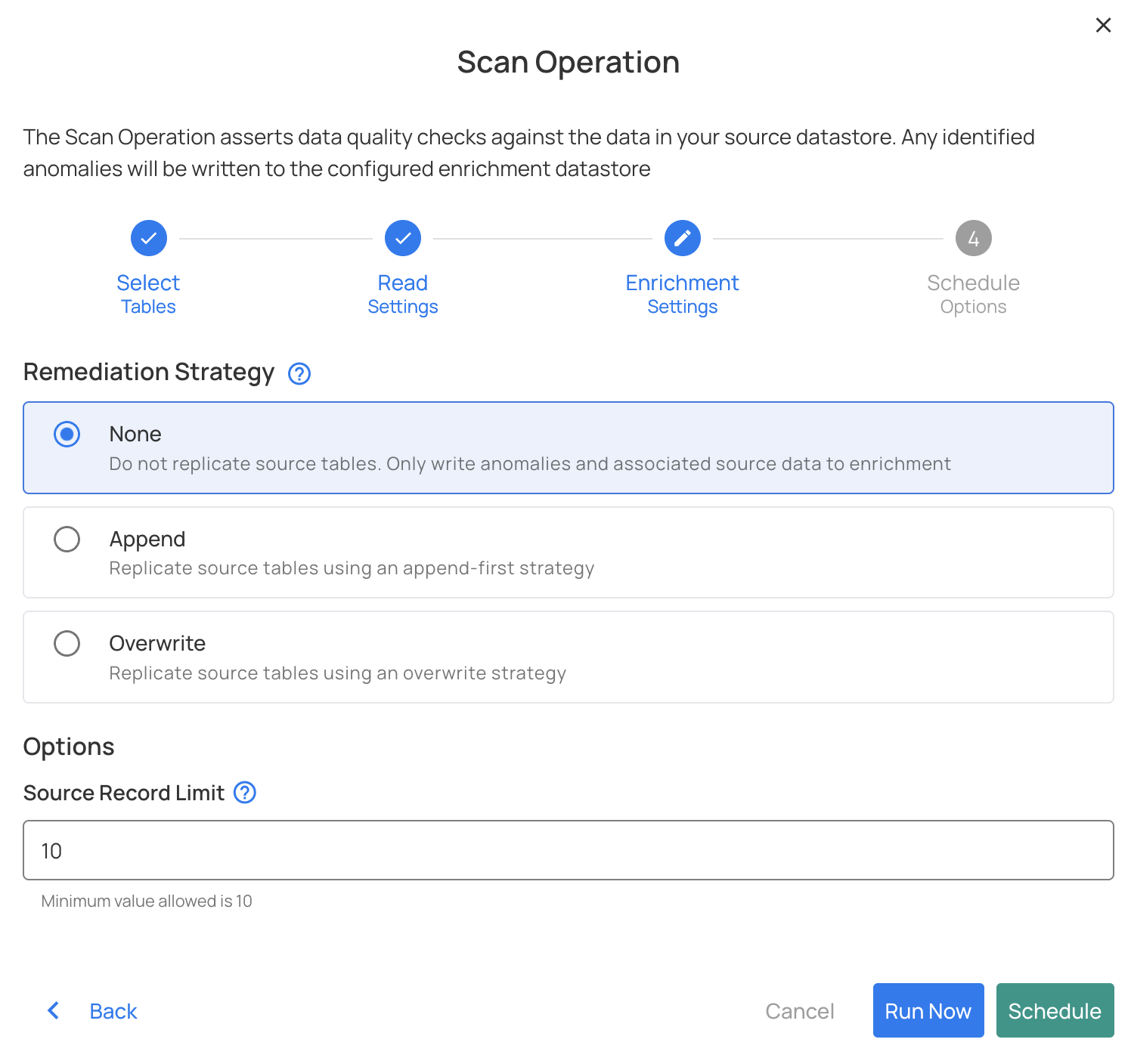
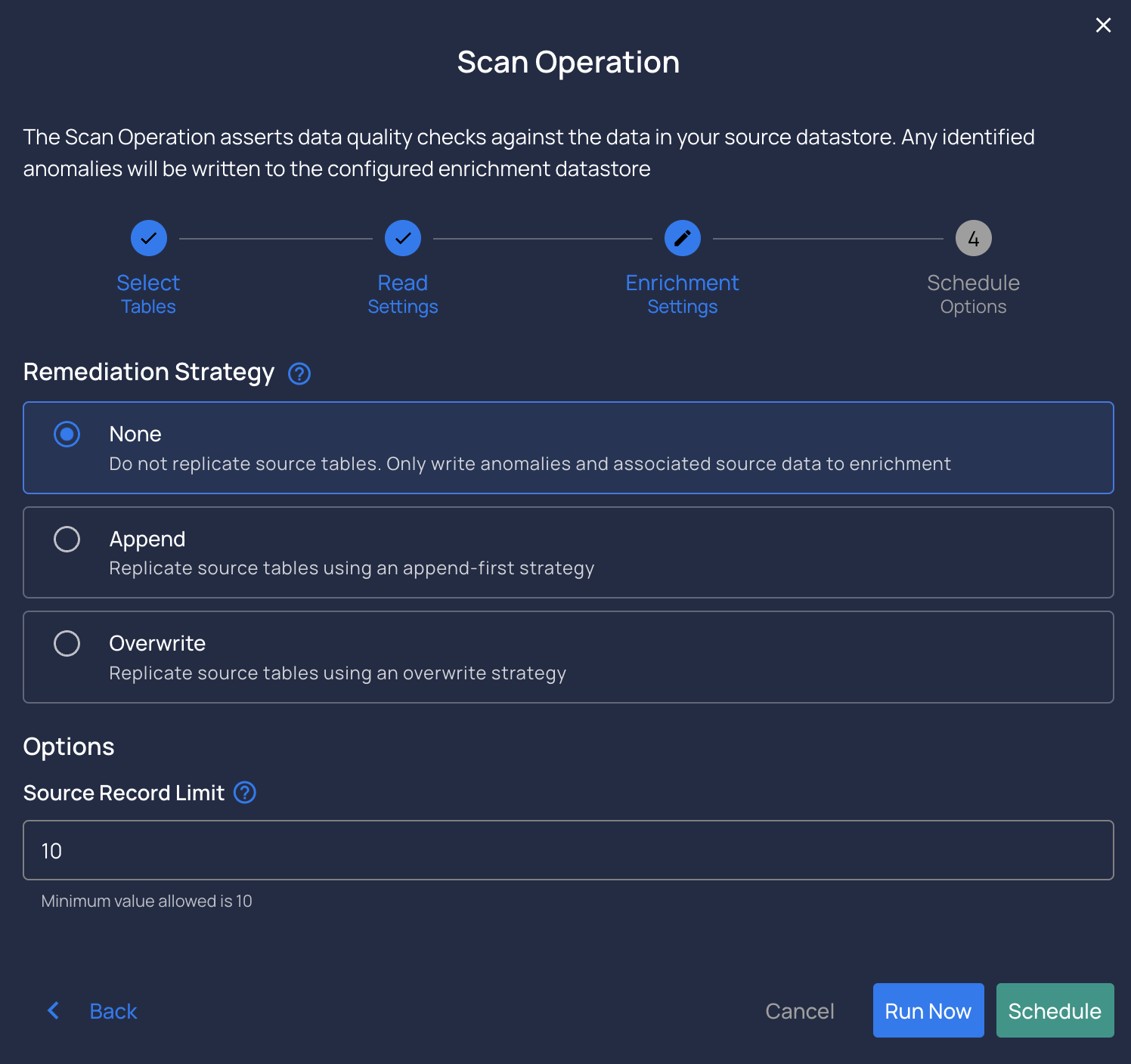
-
There's also an option to schedule the operation by:
HourlyDailyWeeklyMonthlyAdvanced- Cron job expression


Advanced Options
The advanced use cases described below require options that are not yet exposed in our user interface but possible through interation with our API.
Runtime variable assignment
It is possible to reference a variable in a check definition (declared in double curly braces) and then assign that variable a value when a Scan operation is initiated.
Variables are supported within any Spark SQL expression and most commonly used in a check's filter.
If a Scan is meant to assert a check with a variable, a value for that variable must be supplied as part of the Scan operation's "check_variables" property.
For example, a check might include a filter such as "transaction_date == {{checked_date}}" which will be asserted against any records where transaction_date is equal to the value supplied when the Scan operation is initiated. In this case that value would be assigned by passing the following payload when calling /api/operations/run
{
"type": "scan",
"datastore_id": 42,
"container_names": [
"my_container"
],
"incremental": true,
"remediation": "none",
"max_records_analyzed_per_partition": 0,
"check_variables": {
"checked_date": "2023-10-15"
},
"high_count_rollup_threshold": 10
}