Overview of identifiers
An Identifier is a field that can be used to help load the desired data from a Table in support of analysis.
There are two types of identifiers can be declared for a Table:
-
Incremental Field- used to track records in the table that have already been scanned in order to support Scan operations that only analyze new (not previously scanned) data. -
Partition Field- used to divide the data in the table into distinct dataframes that can be analyzed in parallel.
Managing an Identifier
-
You can manage an identifier in the Tables view of a selected datastore, just opening the options of a specific
table:

-
Click on
Settingsbutton:

-
In the pop-up modal, specific configuration is displayed and can be edited:
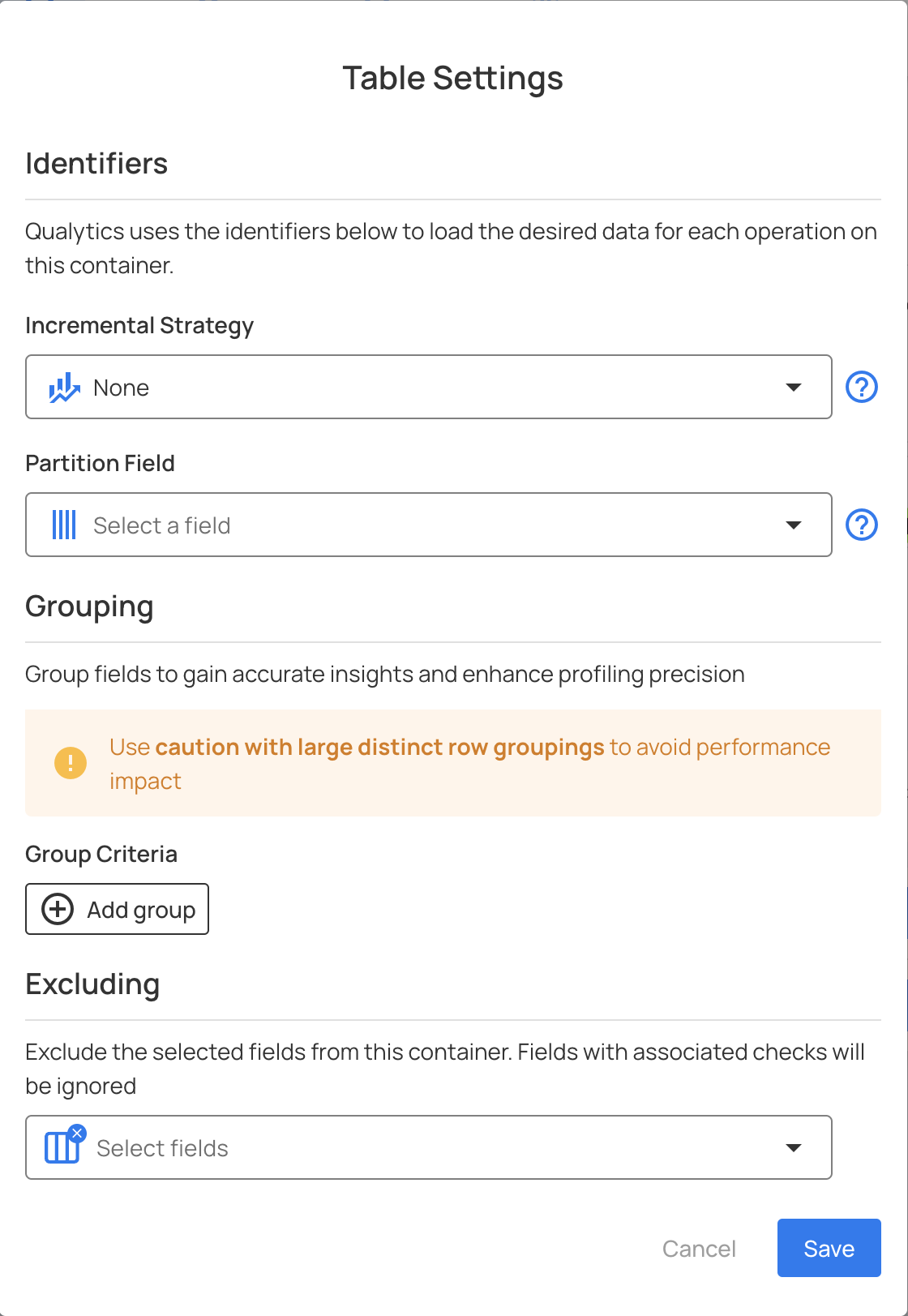
Incremental Strategy
The Incremental Strategy configuration in Qualytics is crucial for tracking changes at the row level within tables.
This approach is essential for efficient data processing, as it is specifically used to track which records have already been scanned.
This allows for scan operations to focus exclusively on new records that have not been previously scanned, thereby optimizing the scanning process and ensuring that only the most recent and relevant data is analyzed.
Options of Incremental Strategy
| Strategy Option | Description |
|---|---|
None |
- No incremental strategy, it will run full. |
Last modified |
- Available types are Date or Timestamp was last modified.- Uses a "last modified column" to track changes in the data set. - This column typically contains a timestamp or date value indicating when a record was last modified. - The system compares the "last modified column" to a previous timestamp or date, updating only the records modified since that time. |
Batch value |
- Available types are Integral or Fractional.- Uses a "batch value column" to track changes in the data set. - This column typically contains an incremental value that increases as new data is added. - The system compares the current "batch value" with the previous one, updating only records with a higher "batch value". - Useful when data comes from a system without a modification timestamp. |
Postgres Commit Timestamp Tracking |
- Utilizes commit timestamps for change tracking. |
Info
- All options are useful for incremental strategy, it depends on the availability of the data and how it is modeled.
- The 3 options will allow you to track and process only the data that has changed since the last time the system was run, reducing the amount of data that needs to be read and processed, and increasing the efficiency of your system.
DFS (Distributed File System) Configuration
For DFS in Qualytics, the incremental strategy leverages the last modified timestamps from the file metadata.
This automated process means that DFS users do not need to manually configure their incremental strategy, as the system efficiently identifies and processes the most recent changes in the data.
PostgreSQL Configuration
PostgreSQL databases in Qualytics offer various options for the incremental strategy:
| Type | |
|---|---|
Postgres Commit Timestamp Tracking |
|
Last Modified |
|
Batch Value |
For other Datastore technologies:
Qualytics provides flexible incremental strategy options:
| Type | |
|---|---|
Last Modified |
|
Batch Value |
Example
Objective: Identify and process new or modified records in the ORDERS table since the last scan using an Incremental Strategy.
Sample Data
| O_ORDERKEY | O_PAYMENT_DETAILS | LAST_MODIFIED |
|---|---|---|
| 1 | {"date": "2023-09-25", "amount": 250.50, "credit_card": "5105105105105100"} | 2023-09-25 10:00:00 |
| 2 | {"date": "2023-09-25", "amount": 150.75, "credit_card": "4111-1111-1111-1111"} | 2023-09-25 10:30:00 |
| 3 | {"date": "2023-09-25", "amount": 200.00, "credit_card": "1234-5678-9012-3456"} | 2023-09-25 11:00:00 |
| 4 | {"date": "2023-09-25", "amount": 175.00, "credit_card": "5555-5555-5555-4444"} | 2023-09-26 09:00:00 |
| 5 | {"date": "2023-09-25", "amount": 300.00, "credit_card": "2222-2222-2222-2222"} | 2023-09-26 09:30:00 |
Incremental Strategy Explanation
In this example, an Incremental Strategy would focus on processing records that have a LAST_MODIFIED timestamp after a certain cutoff point. For instance, if the last scan was performed on 2023-09-25 at 11:00:00, then only records with O_ORDERKEY 4 and 5 would be considered for the current scan, as they have been modified after the last scan time.
graph TD
A[Start] --> B[Retrieve Orders Since Last Scan]
B --> C{Record Modified After Last Scan?}
C -->|Yes| D[Process Record]
C -->|No| E[Skip Record]
D --> F[Move to Next Record/End]
E --> FPartition Field
The Partition Field is a fundamental feature for organizing and managing large datasets. It is specifically designed to divide the data within a table into separate, distinct dataframes.
This segmentation is a key strategy for handling and analyzing data more effectively. By creating these individual dataframes, Qualytics allows for parallel processing, which significantly accelerates the analysis.
Each partition can be analyzed independently, enabling simultaneous examination of different segments of the dataset.
This not only increases the efficiency of data processing but also ensures a more streamlined and scalable approach to handling large volumes of data, making it an indispensable tool in data analysis and management.
The ideal Partition Identifier is an Incremental Identifier of type datetime such as a last-modified field, however alternatives are automatically identified and set during a Catalog operation.
Info
- Partition Field Selection: When selecting a partition field for a table during catalog operation, we will attempt to select a field with no nulls where possible.
- User-Specified Partition Fields: Users are permitted to specify partition fields manually. While we ensure that the user selects a field of a supported data type, we do not currently enforce non-nullability or completeness. Care should be given to select partition fields with no or a low percentage of nulls in order to avoid unbalanced partitioning.
Warning
If no appropriate partition identifier can be selected, then repeatable ordering candidates (order by fields) are used for less efficient processing of containers with a very large number of rows.
Example
Objective: Identify the efficient process and analyze the ORDERS table by partitioning the data based on the O'ORDERDATE field, allowing parallel processing of different date segments.
Sample Data
| O_ORDERKEY | O_CUSTKEY | O_ORDERSTATUS | O_TOTALPRICE | O_ORDERDATE |
|---|---|---|---|---|
| 1 | 123 | 'O' | 173665.47 | 2023-09-01 |
| 2 | 456 | 'O' | 46929.18 | 2023-09-01 |
| 3 | 789 | 'F' | 193846.25 | 2023-09-02 |
| 4 | 101 | 'O' | 32151.78 | 2023-09-02 |
| 5 | 202 | 'F' | 144659.20 | 2023-09-03 |
Partition Field Explanation
In this example, the O_ORDERDATE field is used to partition the ORDERS table. Each partition represents a distinct date, allowing for the parallel processing of orders based on their order date. This strategy enhances the efficiency of data analysis by distributing the workload across different partitions.
graph TD
A[Start] --> B[Retrieve Orders Data]
B --> C{Partition by O_ORDERDATE}
C --> D[Distribute Partitions for Parallel Processing]
C --> E[Identify Date Segments]
D --> F[Analyze Each Partition Independently]
E --> F
F --> G[Combine Results/End]