Overview of a datastore
-
A
Datastorecan be any Apache Spark-compatible data source, such as:- Traditional
RDBMS. - Raw files (
CSV,XLSX,JSON,Avro,Parquet) on:- AWS S3.
- Azure Blob Storage.
- GCP Cloud Storage.
- Traditional
-
A
Datastoreis a medium holding structured data. Qualytics supports Spark-compatible Datastores via the conceptual layers depicted below
Configuration
-
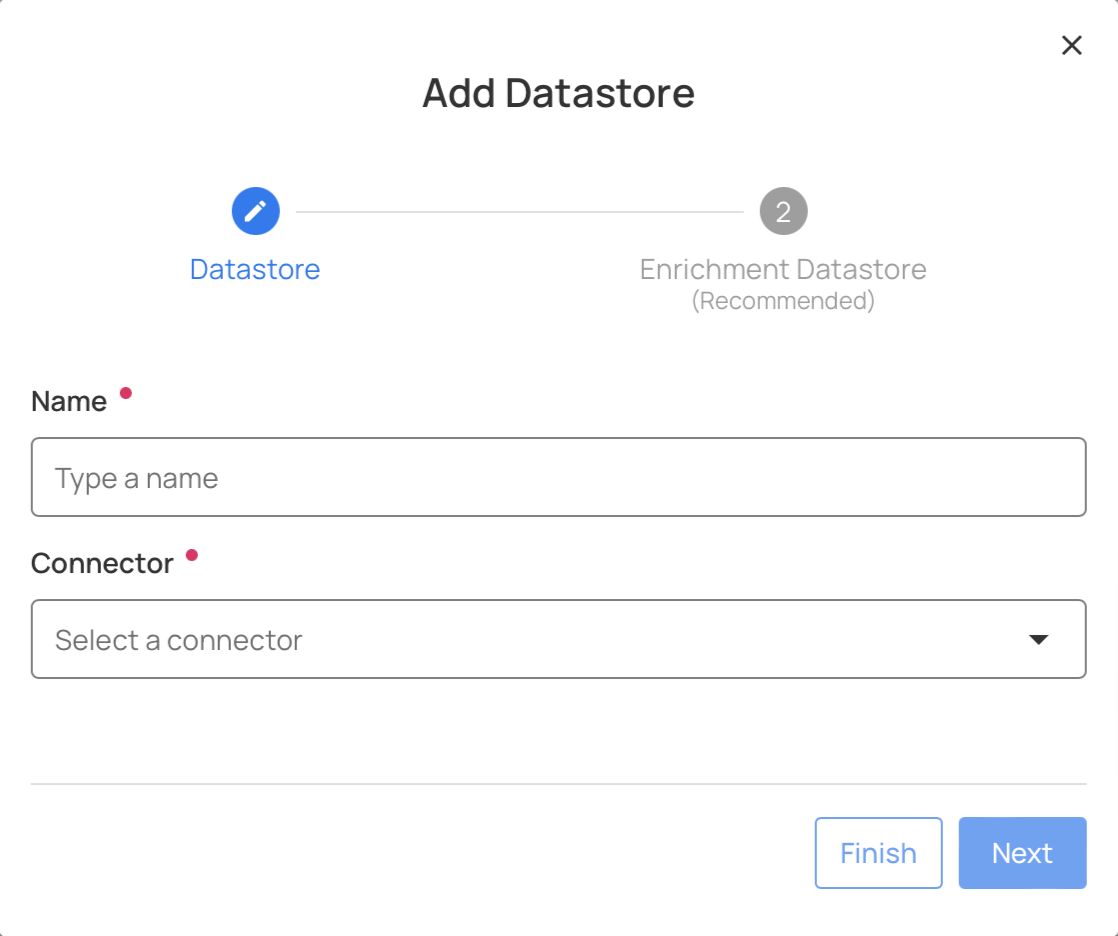
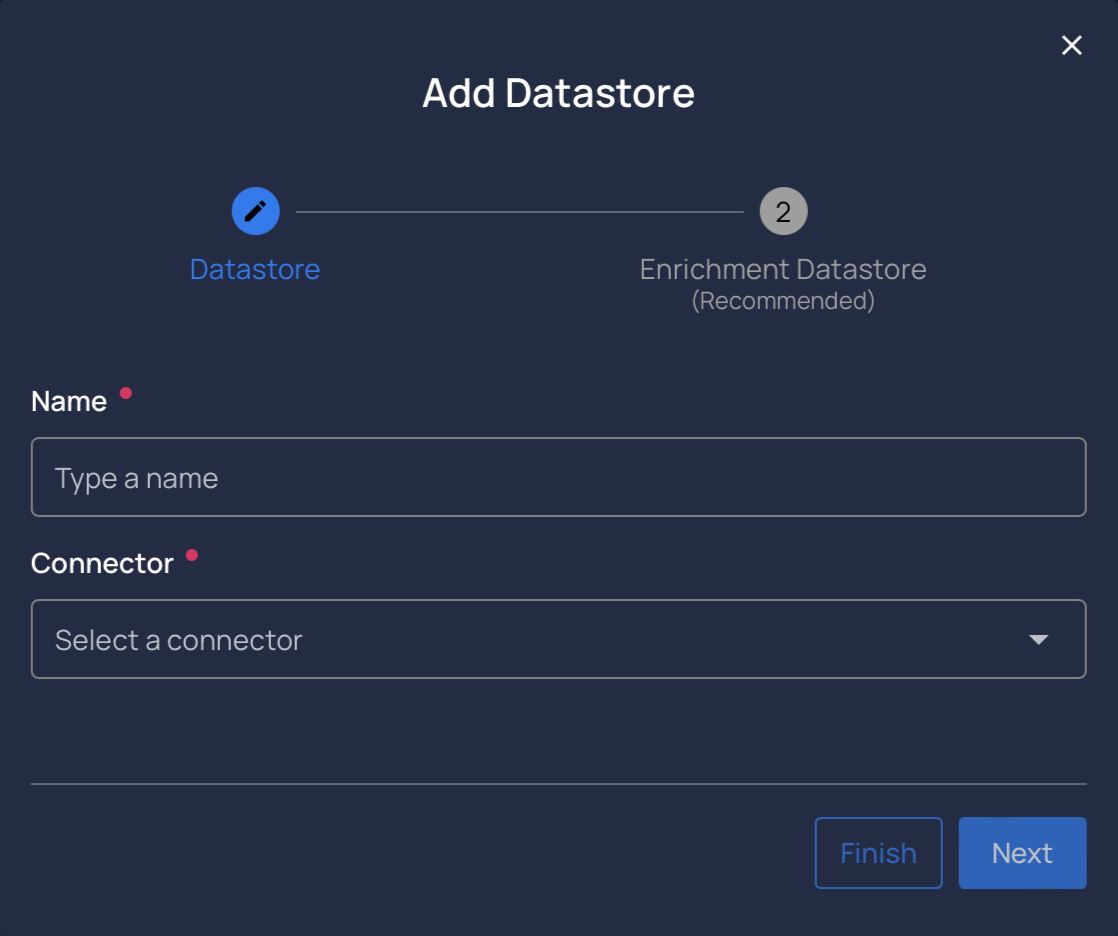
The first step of configuring a Qualytics instance is to Add New Datastore:
- In the
mainmenu, selectDatastorestab -
Click on
Add New Datastorebutton: -


Info
-
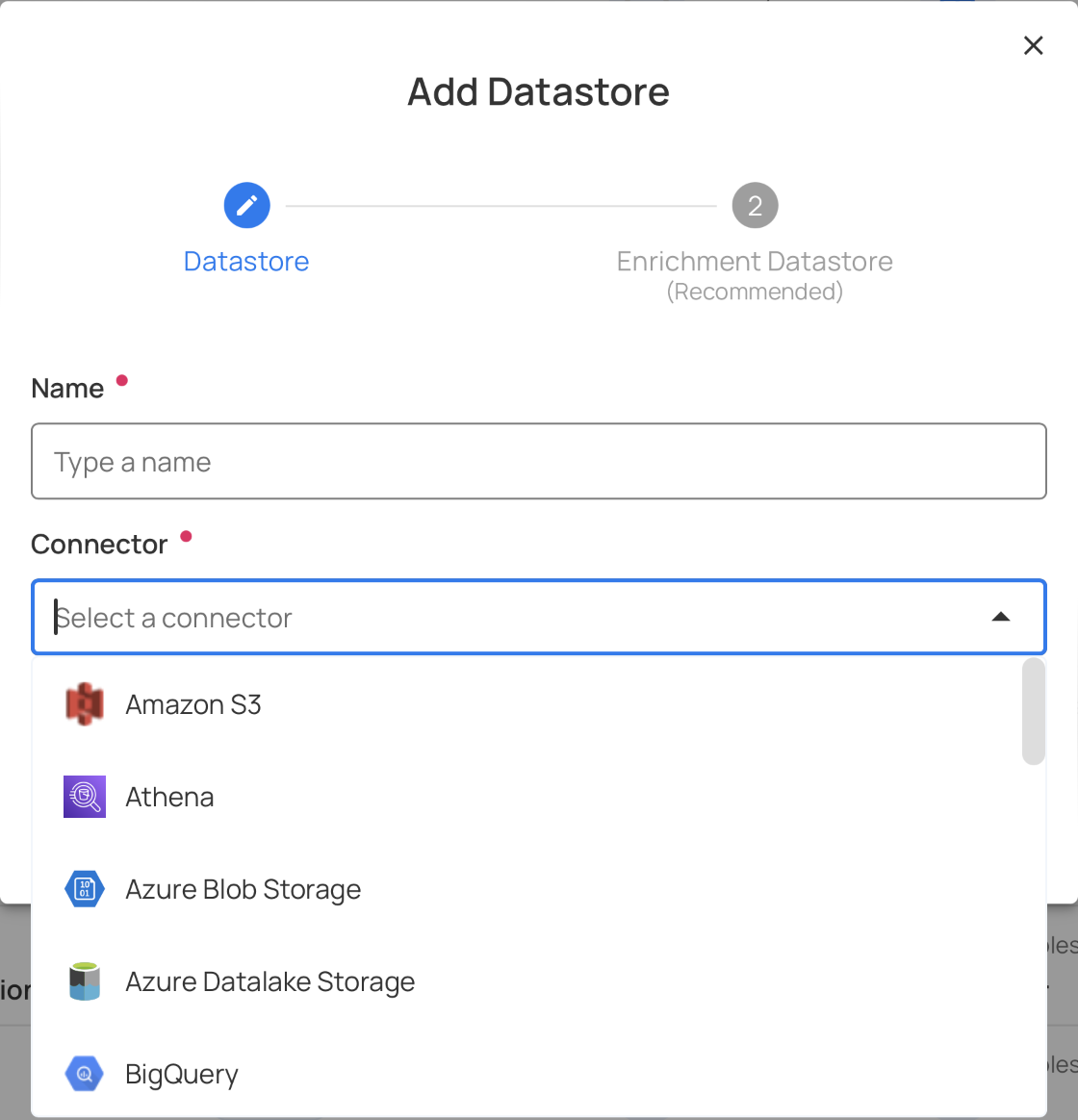
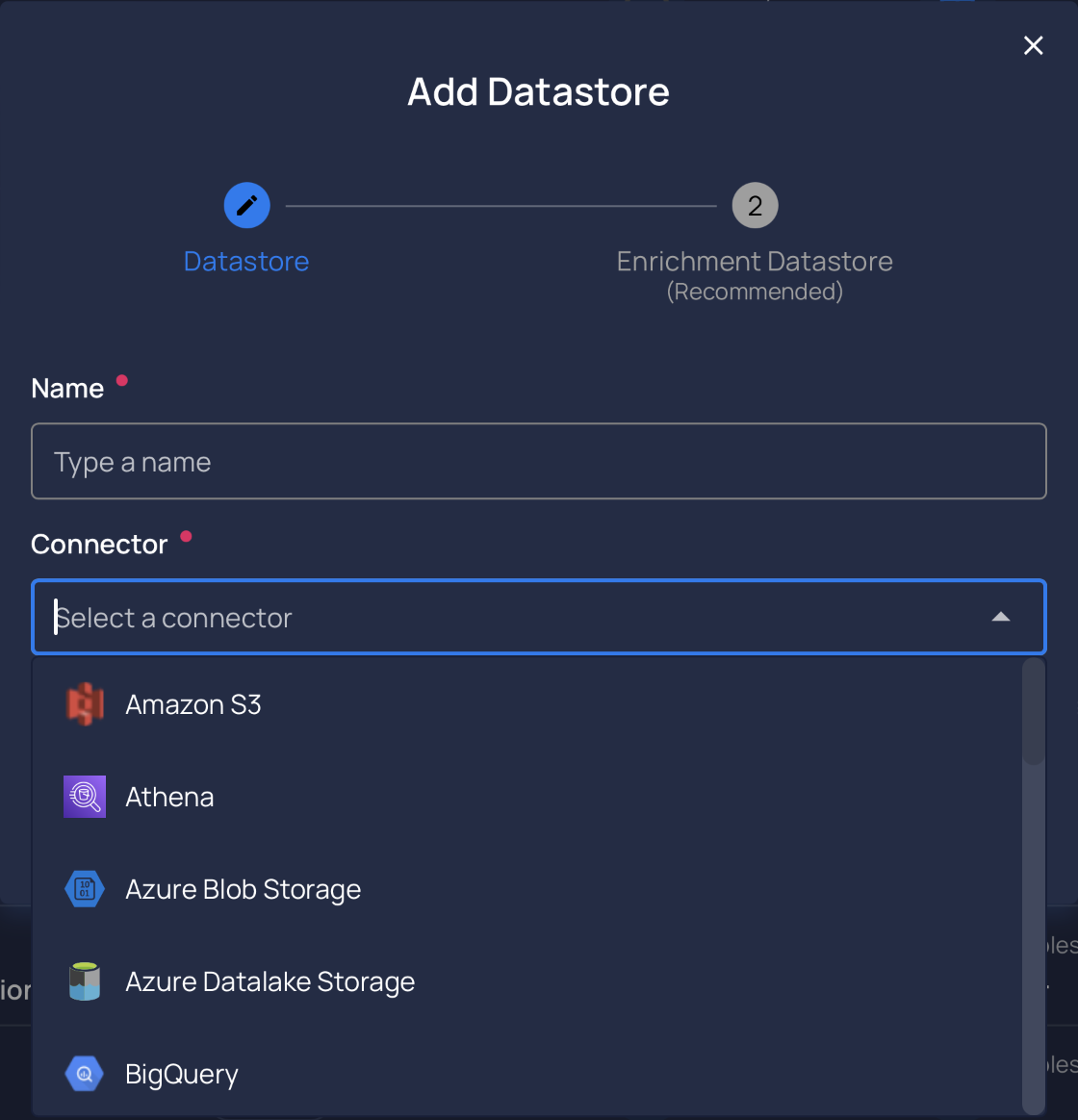
A datastore can be any Apache Spark-compatible data source:
- traditional RDBMS,
- raw files (
CSV,XLSX,JSON,Avro,Parquetetc...) on :AWS S3.Azure Blob Storage.GCP Cloud Storage
- In the
Credentials
-
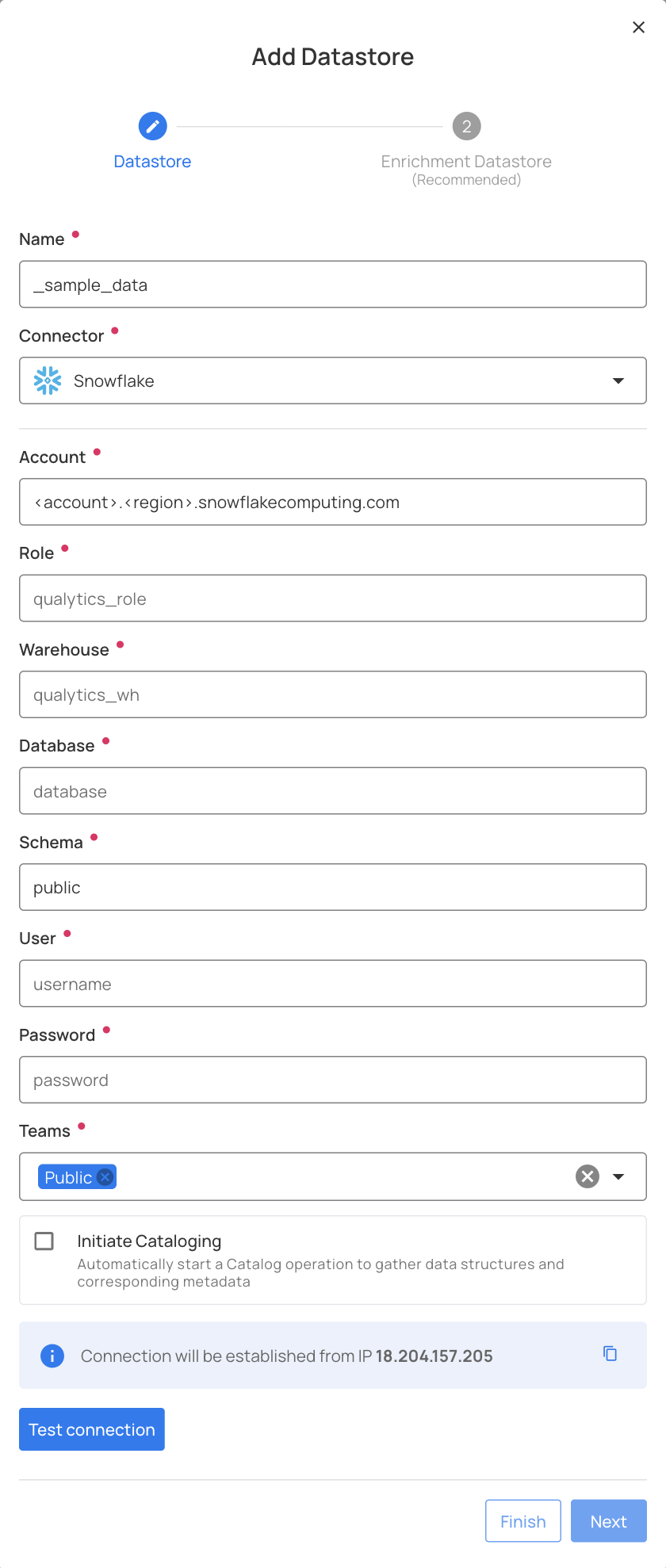
Configuring a datastore will require you to enter configuration credentials dependent upon each datastore. Here is an example of a Snowflake datastore being added:
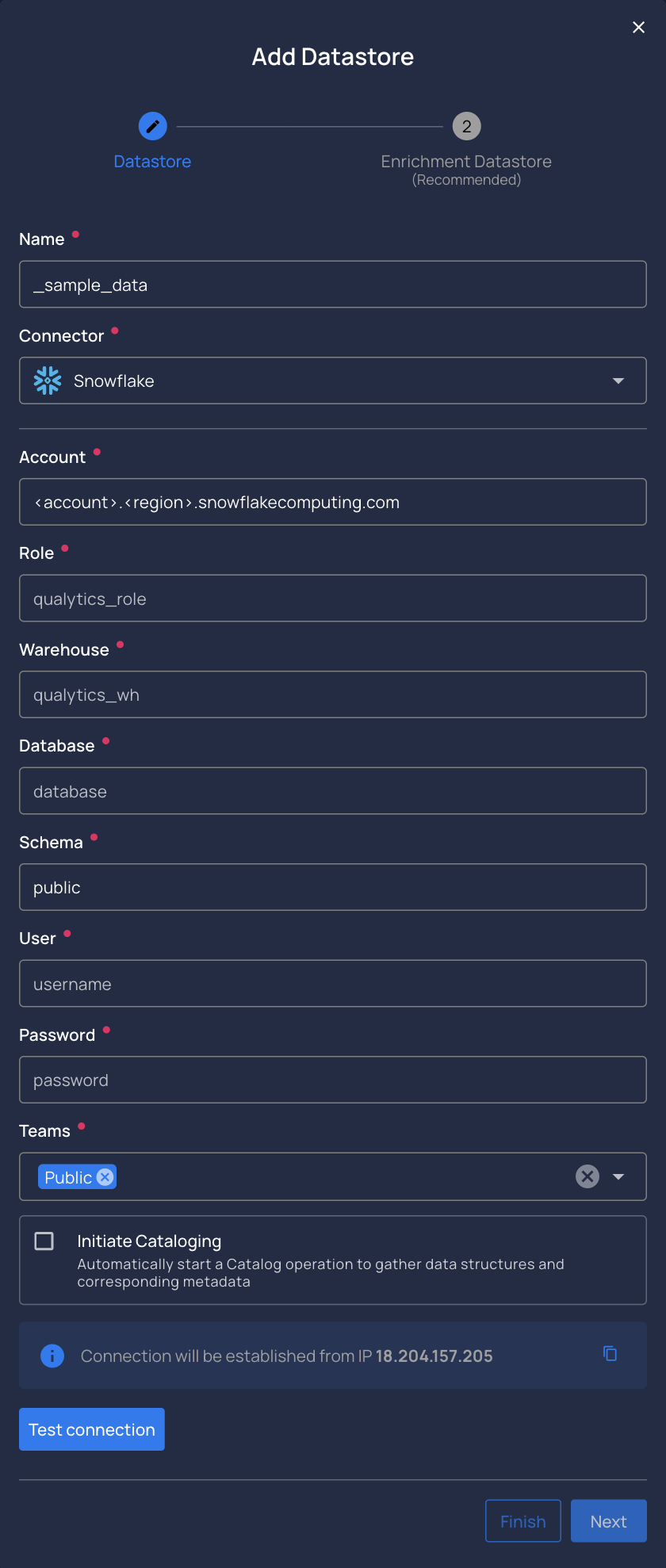
-
When a datastore is added, it’ll be populated in the home screen along with other datastores:
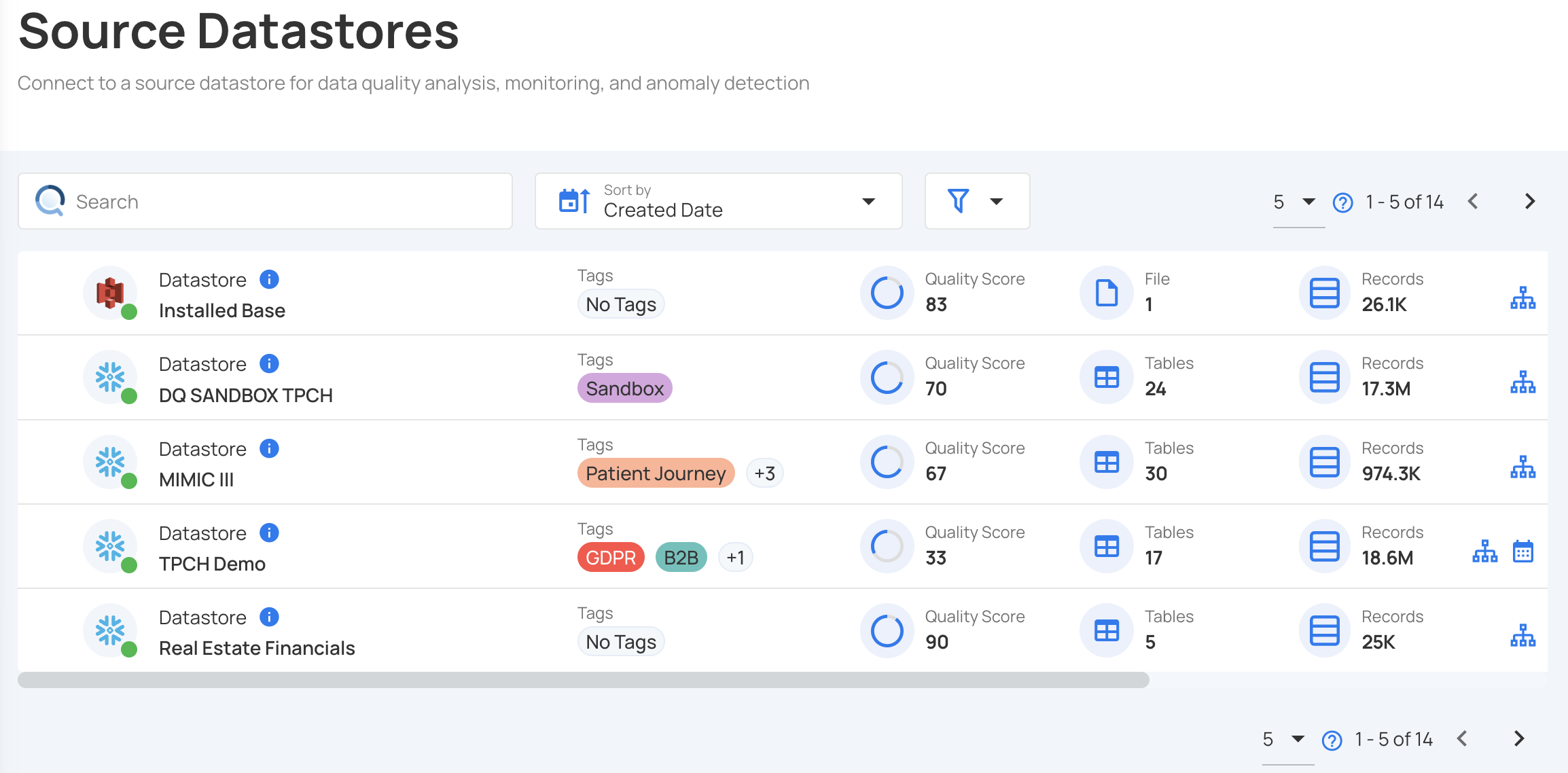
-
Clicking into a datastore will guide the user through the capabilities and operations of the platform.
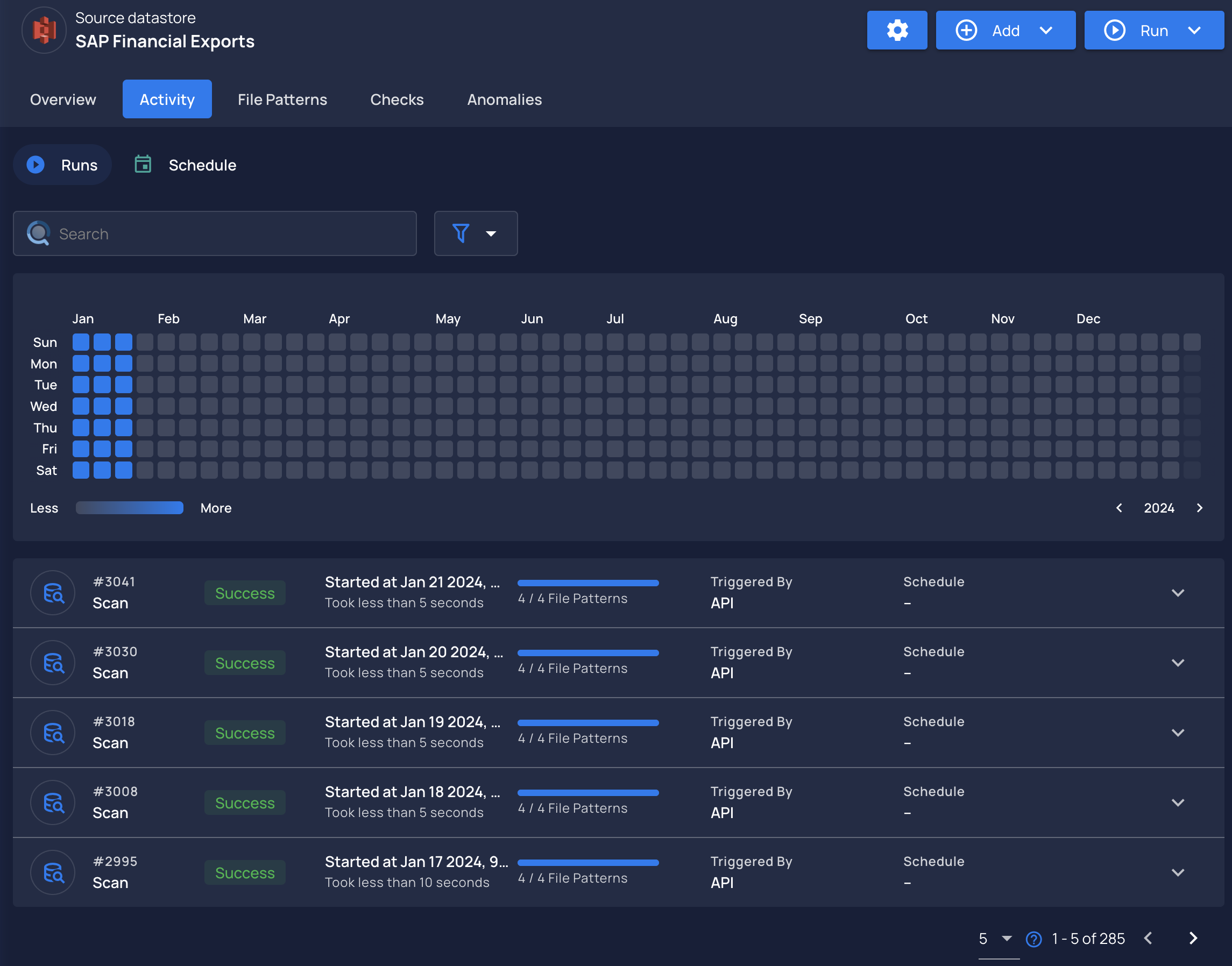
When a user configures a datastore for the first time, they’ll see an empty Activity tab.


- Heatmap view

Running a Catalog of the Datastore
-
The first operation of Catalog will automatically kick off. You can see this through the Activity tab.
- This operation typically takes a short amount of time to complete.
- After this is completed, they’ll need to run a Profile operation (under
Run->Profile) to generate metadata and infer data quality checks.